Anomaly Detection with Privacy-preserved Peer-to-peer Federated Learning
In the context of IoT, the augment of the computational power and capacity of edge devices enables the use of distributed ML approaches, pushing the computation of the models to these edge devices. Federated Learning (FL) has emerged as a very promising paradigm for training distributed ML models. FL allows to train a ML model collaboratively so that each participant in the learning task trains the model locally using their own datasets. Peer-to-peer FL (P2PFL) has, recently, caught researchers’ eyes within the federated learning domain. P2PFL tries to remove the cloud and global model from the FL process, which means the clients update their local model by directly interacting with its connected neighbour clients and there is no need of an orchestrator for coordinating the learning process.
Non-IID and Imbalanced data
P2PFL, however, still suffers from FL’s challenges: imbalanced and non-Independent and Identically Distributed (non-IID) data. It is because, in a real-world setup, the collected data varies significantly among devices since user’s preferences and local environments are different. This is especially relevant for IoT anomaly detection, as the type of attacks or anomalies observed by each device can be different and, in many cases, the anomalous data can be scarce.
From the smaller scope, an important aspect is that the local on-device datasets are usually non-IID which has been shown to degrade model’s performance [1]. For example, Zhao et al [2] pointed out that the prediction accuracy dropped by up to 11% for MNIST and 51% for CIFAR-10 in the case of non-IID datasets. This degradation is expected to be more severe in imbalanced dataset scenarios, which cause the model to be biased in favor of the well represented classes. From the bigger scope, the global model usually enforces a bias towards patterns provided by the majority of clients, while suppressing patterns of minor clients [3]. In the context of application of anomaly detection this means that the global model may not be able to correctly predict anomalies that have been only observed by a small number of participants, which limits the benefits of training a collaborative model.
RISE Research Institutes of Sweden and Imperial College London ICL are investigating how to address the problem of anomaly detection in the context IoT networks, where the data are regularly imbalanced and non-IID distributed. We leverage peer-to-peer learning, which allows to train a collaborative model without the need of a central node. We propose a data re-balancing mechanism for P2PFL. By taking the advantages of P2PFL, we adaptively improve SMOTE, a state-of-the-art re-balancing technique, by generating more complex synthetic points to share some of them with other participated clients during the training of a P2PFL task. These shared points help other clients to re-balance their own local dataset and add more variance to it, which can prevent model from degrading in non-IID settings.
System Design
Within an IoT network, our system can be employed on the edge devices, which is seen as the client in FL set up. The edge device can be a gateway that monitors the network traffic in order to detect any abnormal behavior. In contrast to traditional FL, in P2PK-SMOTE, the cloud, which is the central node, does not participate or orchestrate the training process except for the deployment of the initial model.
Figure 1 depicts how our system works. Overall, the system consists of three phases: 1) re-balancing, 2) optimization of the anomaly detector, and 3) sharing. In the first phase we re-balance the training data in the clients (devices) with over-sampling (i.e. augmenting the number of data points from the minority class), by generating synthetic data points from the genuine data points in the minority class. The synthetic data points are fed into the anomaly detector together with the original dataset owned by the client so that the fraction of benign and malicious data points is similar. Then, the anomaly detector is optimized with this combination of genuine and synthetic data points. Finally, the resulting model and a fraction of the synthetic data points generated are shared with a subset of the connected clients.
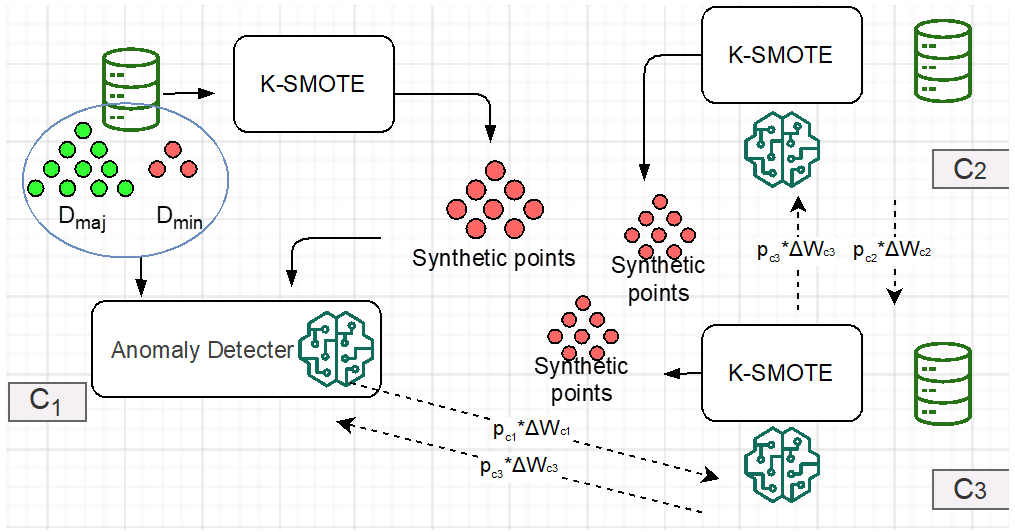
Figure1: System overview: Each client contains its local dataset, K-SMOTE, and a local model for anomaly detection. The local dataset contains samples from both the majority (green dots) and the minority (red dots) classes.
Findings and benefits of our approach
The cause of non-IID phenomenon is heterogeneity of various IoT devices, and this phenomenon degrades the model’s performance in FL. It is bound to sacrifice some privacy to solve the problem of non-IID. However, our system creates a win- win way, which can solve the problem, but also without losing privacy during the collaborative learning task. We propose to share some artificial data between some participants to help their local data re-balancing. And, our system proofs its effectiveness by empirical results.
In the assumption that there are no compromised clients in FL set up, our system brings a new anomaly detection method that is adaptive to imbalanced and non-IID data in IoT network. From security perspective, our system is more reliable and trustworthy. However, it considers any adversarial attack targeting the learning algorithm itself, both at training or at test time. For this, at training time, robust aggregation schemes, similar to those used in FL, are needed to defend against data and model poisoning attacks. At test time, we can resort to adversarial training to mitigate the impact of adversarial examples aiming to evade detection. The combination of these techniques to defend against such attacks with the re-balancing mechanisms proposed in this paper is left for future work.
More details can be found in our published paper “Non-IID Data Re-balancing at IoT Edge with Peer-to-peer Federated Learning for Anomaly Detection” in ACM WiSec’21, contributed by Han Wang, Luis Muñoz-González, David Eklund, and Shahid Raza,
References
[1] H. Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Agüera y Arcas. 2016. Communication-Efficient Learning of Deep Net- works from Decentralized Data. arXiv:1602.05629 [cs.LG]
[2] Yue Zhao, Meng Li, Liangzhen Lai, Naveen Suda, Damon Civin, and Vikas Chan- dra. 2018. Federated Learning with Non-IID Data. (2018). arXiv:1806.00582 [cs.LG] [3] Amira Soliman, Sarunas Girdzijauskas, M.-R Bouguelia, Sepideh Pashami, and Slawomir Nowaczyk. 2020. Decentralized and Adaptive K-Means Clustering for Non-IID Data Using HyperLogLog Counters. Advances in Knowledge Discovery and Data Mining: 24th Pacific-Asia Conference, PAKDD (05 2020), 343–355. https://doi.org/10.1007/978- 3- 030- 47426- 3_27
(By Shahid Raza, (RISE))